In a world where autonomous systems are becoming more numerous, there is pressure to build similarly autonomous agents to observe these systems for anomalous behavior. Given the complexity of the systems, and the fact that it is not economically viable to employ humans to observe them, we must find a way of algorithmically solving this problem.
The incredible speed of modern computers, and improvements to machine learning algorithms provide us with an extensive toolkit with which to perform anomaly detection. Furthermore, cloud computing and low-powered edge devices offer us the ability to train complex models and run them inexpensively on affordable devices.
There are three methods we can employ when detecting anomalies; Kmeans clustering, Markov chains, and neural networks. In this blog we will discuss how each method can relate to a specific use case, as well as other possible scenarios and technologies.
Anomaly detection in a household
How can a machine be taught which are anticipated day-to-day activities and which are potential threats? Think of the variables involving human activity and how unpredictable we can be! How can a machine be taught to recognize typical and atypical behaviour?
Algorithms.
Our specific use case was the detection of anomalous behaviour within a household, training an agent in the cloud and deploying it to execute in real-time on a low-powered edge device, in our case a Raspberry Pi. After monitoring the typical activity for a month and collecting the data, our agent had what was needed to establish an accurate activity baseline so that anomalous behavior could be highlighted in real-time.
Given the sporadic nature of human behavior, and the generality of the problem, this was a particularly difficult problem to solve. Explicit algorithms could not be used, due to the infinitude of edge cases and exceptions to rules.
More associative and self-organizing models were required to solve this, in particular, these three distinct methods:
Kmeans
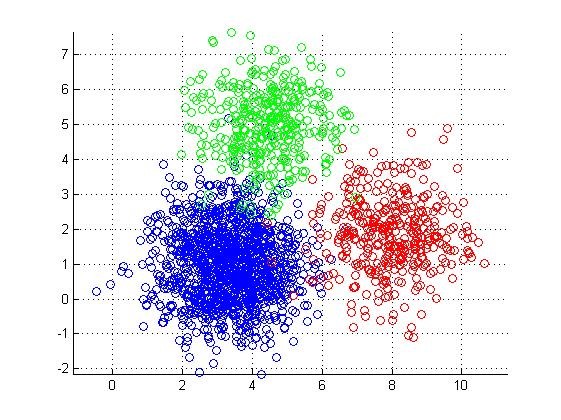
Kmeans is a clustering algorithm that groups objects based on their features.
Objects with similar features will be closer together than ones with different features, and categories can be formed based on this proximity.
For our specific use case, we created n-dimensional vectors by combining motion sensor events into activities. These activities could then be clustered based on features (in this case, the features were the on/off state of the motion sensor ids). To test anomalous behavior, we checked if new activities fell outside of the normal behaviour as represented by the clusters.
If they did, these outliers were considered to be anomalous.
Markov Chains
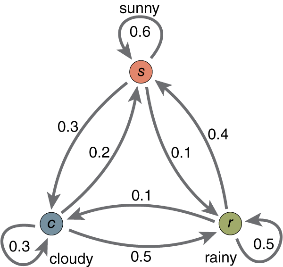
A Markov chain is a state-transition graph with weighted edges that represent the probability that any state will transition to another.
This is useful in anomaly detection because we can set a threshold of minimum transition probability observed during normal behavior.
For our use case, we found the minimum probability of one motion sensor transitioning to another, and any subsequent transitions that fell below this threshold was labelled anomalous.
Neural Network - LSTM
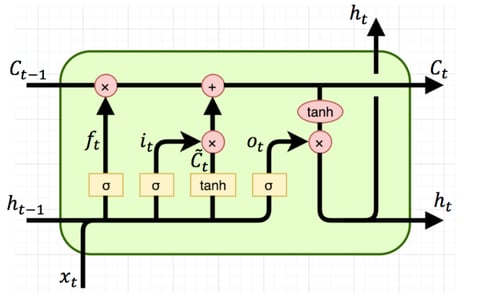
An LSTM is a variant of a neural net that models temporal information.
It is often used for prediction, which makes it useful for applications like natural language processing.
Predicting the next household activity, given a history of past activities was where LSTM was applied for this case. This essentially built up a model of normal behavior, which then allowed us to identify anomalous behavior as an activity that the LSTM did not expect.
Results
Human behavior is very unpredictable, which makes it the perfect testing ground for machine learning. We were able to draw out many of the anomalies in our test data, and reasonably manage the false positives.
Each algorithm had its pro’s and con’s; Kmeans and the Markov chain had very low false positives but were very simplistic and did not generalize well.
The LSTM was more complex and generalizable but had a greater number of false positives.
Interpreting results using statistical methods such as a Multivariate Gaussian Distribution improved our abilities to effectively manage the data.
Applications
The value of this project is not just measured in the success of detecting anomalies in a household, but in the multitude of technologies anomaly detection can be applied to. Given the unsupervised nature of these algorithms and the difficulty of the use case, we are confident that these methods can be applied to complex systems with only raw metrics to work from.
Possible applications include; intrusion detection in network traffic, system health monitoring, fraud detection, predictive maintenance, and industrial system monitoring, to name a few.
Anomaly detection allows companies to identify a fault as soon as it happens (and even before that with predictive maintenance), saving on repairs, security breaches, and other undesirable outcomes.
How are you currently detecting and monitoring anomalous behaviours?
Mark Giroux is a software developer and research analyst in our innovation lab, and did the majority of the implementation work for the profiled project.
Please add your inquiry or comments for Mark in the form below and he'll be sure to get back to you!



Submit a Comment